本文档作者为Luke(wlg)。
本文档最初是课程报告,现做了少量改编仅供学习交流使用。
未经允许,严禁复制、转载或引用文档的任何部分!特此声明!
1 项目概述
人脸识别在现代社会中有着非常广泛的应用。此次数字图像处理课程中,我选择做一个基于深度学习的人脸识别系统。我设计的基于深度学习的人脸识别系统,通过摄像头获取图片,使用dlib分类器定位人脸,使用卷积神经网络进行人脸识别。我设计的系统有三个输出类别。除了可以识别我和另外一个同学外,我还在网络上的LFW人脸图片库中下载了一定的图片,来作为第三个类别为图片标记标签。关于系统的详细设计思路和实现过程将在下面几个部分进行详述。
2 模块功能和结构划分
我实现的系统共分为摄像头采集和处理图片模块、本地图片处理模块、卷积神经网络搭建和训练模块以及测试模块四个部分,每个部分保存在一个.py文件中。
摄像头采集和处理图片模块主要负责采集人脸图片,通过调用摄像头截取照片,定位人脸,指定规格化,并最终保存人脸图片。
本地图片处理模块主要用于处理我在网络上下载下来作为第三个分类类别使用的图片,其主要功能是将图片读入,使用dlib定位人脸,然后将人脸图片保存成我设定好的规格以便使用。
卷积神经网络搭建和训练模块主要完成前向传播、划分训练集与测试集、反向传播等功能,是整个系统的关键部分。
测试部分主要来调用摄像头捕获人脸图片,然后读入之前保存好的训练成熟的网络进行识别。
系统结构如下图所示:
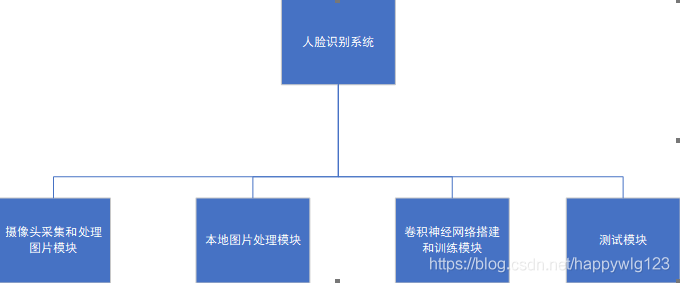
图 1系统结构
3 项目实现
3.1 样本的采集和处理
样本的采集和处理主要集中在摄像头采集和处理图片模块、本地图片处理两个模块中。
首先,使用摄像头采集和处理图片模块来采集和处理我和另外一个同学的图片。使用OpenCV调用摄像头,然后截取图片并灰度化,之后使用dlib找到人脸并以合适的规格保存图片。具体流程如下图所示:

图 2采集流程
在网上下载LFW图片库的图片并不符合我想使用的规格,所以设计了本地照片处理模块。在本地照片处理中,流程基本和上面一致,不同的地方在于输入不再从摄像头中读入,而是本地的图片。具体流程如下图所示:

图 3本地图片处理流程
下面来解释与样本采集与处理有关的关键代码。
首先使用**camera = cv2.VideoCapture(0)**来打开摄像头,在经过灰度化处理后,使用dlib分类器定位人脸,获取到相应的坐标。
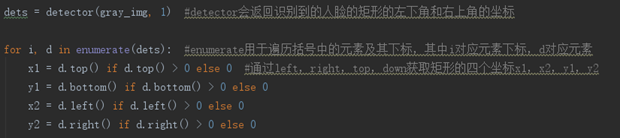
图 4定位人脸坐标
获取到人脸的左下角和右上角坐标后,在通过摄像头获取的图片中把人脸截取出来,保存成我们想要的规格。可通过代码face = img[x1:y1,x2:y2],face = cv2.resize(face, (size,size))来完成。
在完成对图片的采集和处理后,接下来进行神经网络的搭建工作。
本文档作者为Luke(wlg)。
3.2 卷积神经网络的构建和训练
3.2.1 卷积、池化、激活和舍弃
卷积层在整个网络中具有重要的作用,用来提取样本的特征并进行处理,选择好卷积层对整个卷积神经网络识别的准确率有重要的影响。在选择卷积核的时候,一般采用“小卷积核,多卷积层数”的原则。因此,我最终采用了在图像识别中非常常用的三层卷积的结构。卷积核大小采用3乘3,在行和列上的移动步长均定为1。为了保证样本在经过卷积层后规格不变,方便下一步处理,我使用了“全零填充”,也就是在样本外面加一层“0”。
在每一层卷积层后,我都连接了一个池化层,采用最大池化来进行下采样。我将池化层的分辨率定为2乘2,也就是将卷积后的样本分成了很多个2乘2的小区域,在每个小区域里采集最大值,然后合并起来作为池化层的输出结果。用于池化的原因,虽然卷积过后样本规格并没有发生变化,但是池化会使样本的长宽减小一半。
在完成池化后,我又让样本过了一次激活函数。激活函数的作用是给神经网络加入一些非线性的因素,使得神经网络可以更好的解决分类问题。在选择激活函数的时候,我采用了relu函数。我经过查阅文献发现,当前很多文献都推荐使用relu函数,原因是它的计算代价小并且能够减轻梯度消失的问题。为了减小训练时间,我最终选择了使用relu函数。
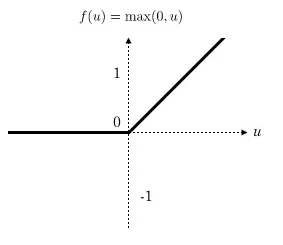
图 5relu函数示意图
在完成激活往下一层网络输入前,我又引入了舍弃。引入舍弃的原因在于,我们构造的网络需要训练的参数普遍很大,而且很容易产生过拟合的问题。为了增强模型的泛化性,可以通过舍弃,随机的让某些参数不参与训练。但是,舍弃仅仅是针对训练阶段而言的,在模型真实使用的时候,所有的参数都是要参与到计算中来的。
最终,这一部分的网络结构如下图所示:

图 6结构示意
在我设计的网络结构中,首先将准备好的样本输入(64643),经过卷积后,样本规格不变,但是通道数由3变为了32。然后经过池化层时,样本的长宽各减半,所以在经过第一层卷积和池化后,样本规格变为了323232。其他层的计算方法与第一层完全相同。在经过了第二层卷积核池化后,样本规格变为了161632。在经过了第三层卷积核池化过后,样本的规格变为了8864,并作为输入进入到全连接神经网络中。
代码上,配置卷积层、池化层以及使用激活函数和引入舍弃,都可以通过调用TensorFlow里的函数实现,为了方便起见,可以自己定义函数,在里面再调用TensorFlow的函数,这样只需要在自己的函数里把TensorFlow需要的参数配置好,以后只需要调用自己的函数传样本和待优化参数就可以了。具体如下所示:



图 7自己包装好创建卷积、池化、舍弃的函数
3.2.2 全连接神经网络
在全连接神经网络中,我主要设置了一层隐藏层和一层输出层。根据我查阅的文献,增加隐藏层的层数可以降低网络误差,但是同时增加了网络的复杂性,容易使网络产生过拟合的倾向,因此往往通过增加隐藏层节点个数来获得较低的误差比增加层数要好一些。
为了确定设置多少个隐藏层节点较好,我进行了一些尝试,分别尝试了256、512、1024三种隐藏层节点情况下网络在测试集上的准确率。
为了控制变量,将输入样本确定为6000,其中我、我srf的搭档以及第三分类图片各2000张。训练集和测试集的比例设置为95:5,batch_size设置为100个样本,执行400个batch_size后停止。
256、512、1024个隐藏层节点下的测试集准确率和loss如下图所示:
…
请进入github链接获取源代码和全文:https://github.com/lukegood/DIY_Face_recognition_system